|
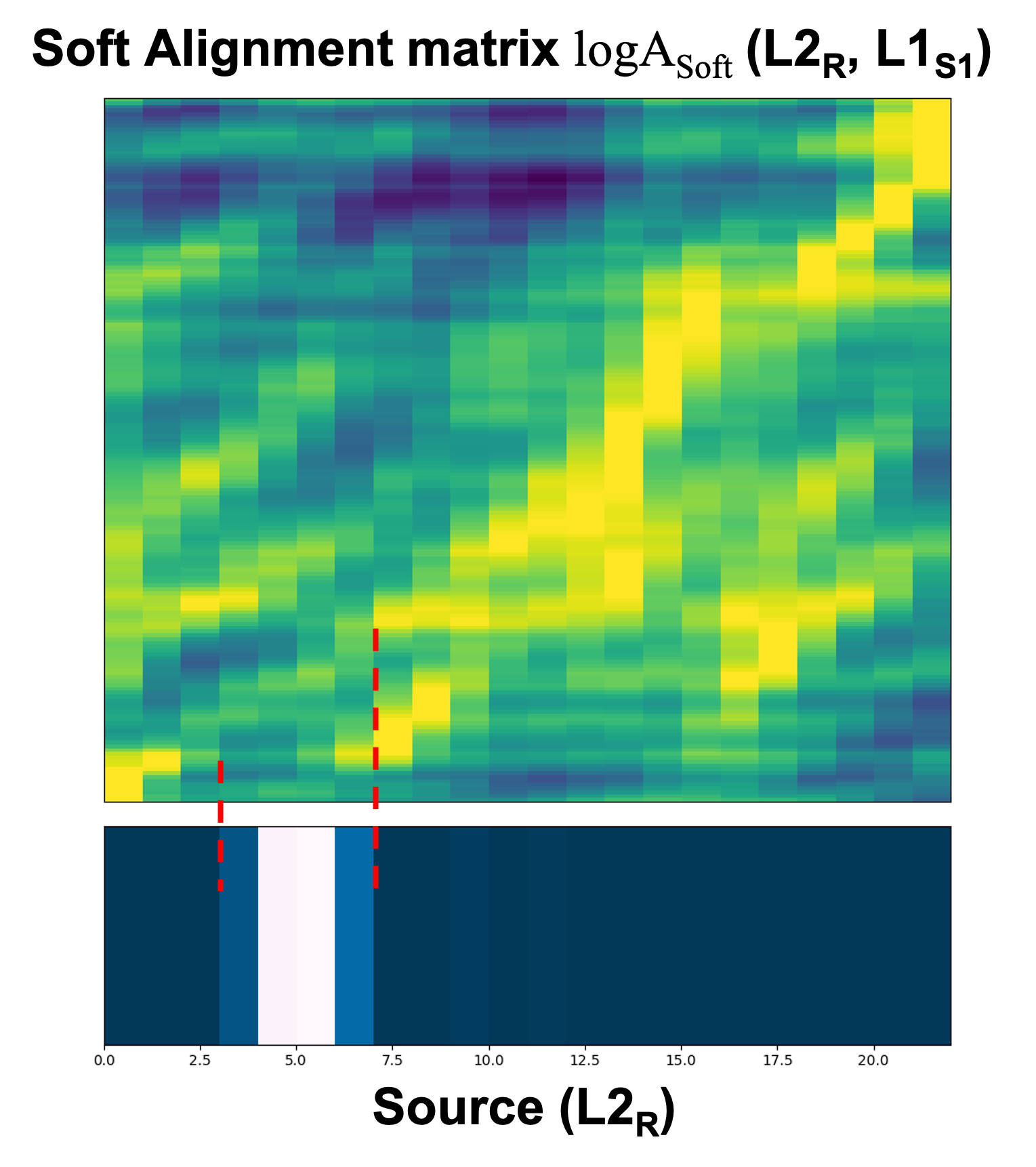
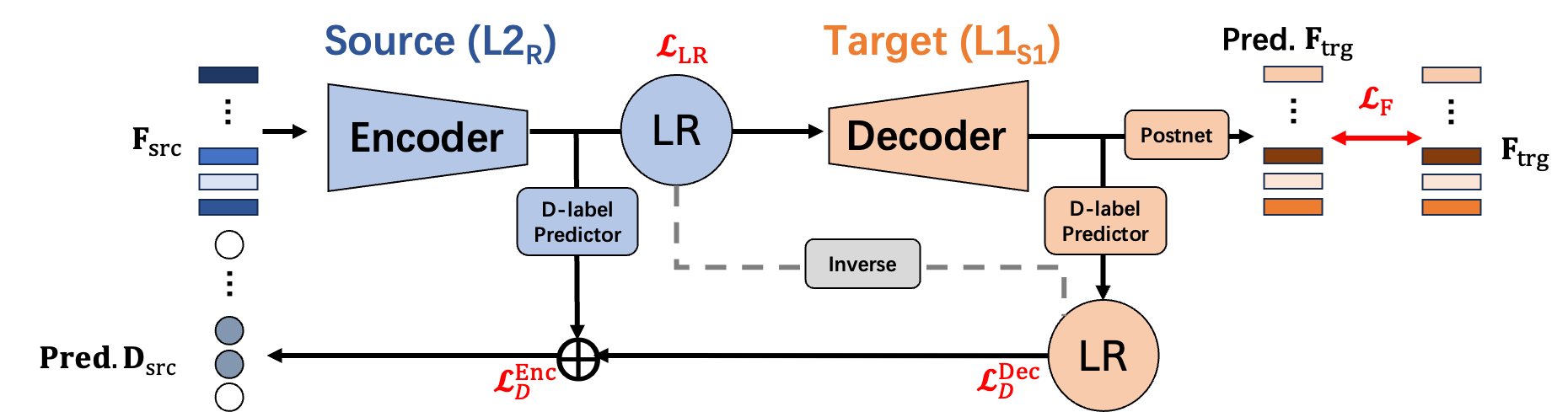
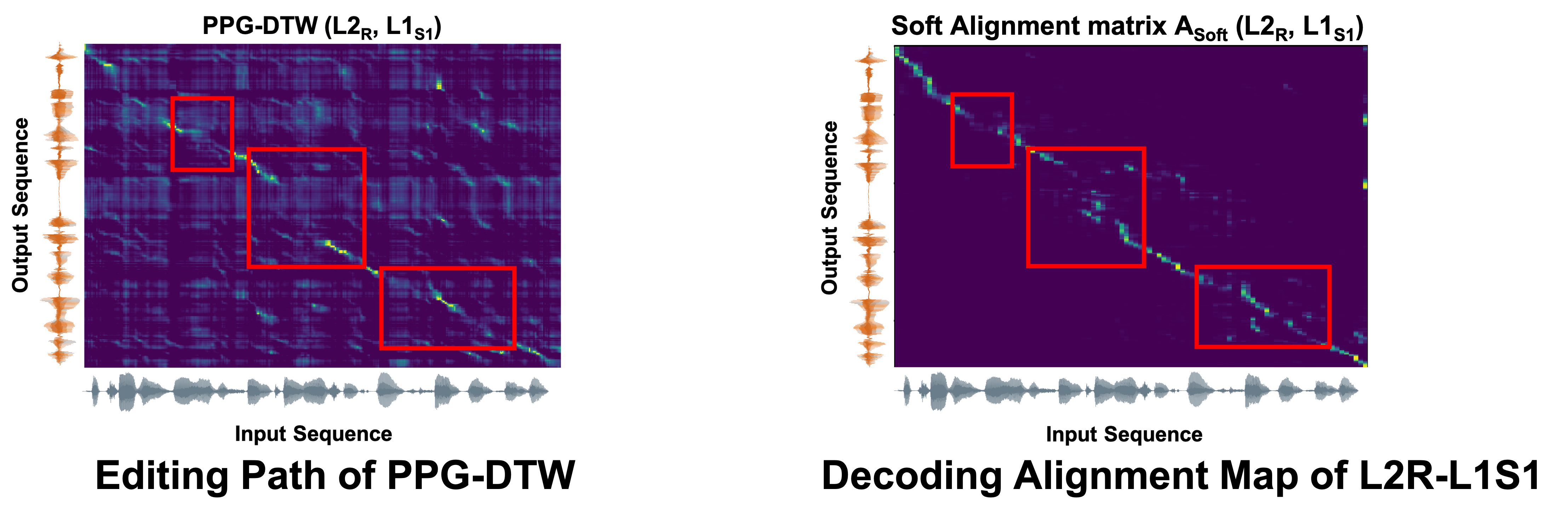
Evaluating L2 speech intelligibility is crucial for effective computer-assisted language learning (CALL). Conventional ASR-based methods often focus on native-likeness, which may fail to capture the actual intelligibility perceived by human listeners. In contrast, our work introduces a novel, perception-based L2 speech intelligibility indicator that leverages native rater’s shadowing data within a sequence-to-sequence (seq2seq) voice conversion framework. By integrating an alignment mechanism and acoustic feature reconstruction, our approach simulates the auditory perception of native listeners, identifying segments in L2 speech that are likely to cause comprehension difficulties. Both objective and subjective evaluations indicate that our method aligns more closely with native judgments than traditional ASR-based metrics, offering a promising new direction for CALL systems in global, multilingual contexts.
|
|