
Haopeng (Kevin) Geng is a Ph.D. candidate in the Department EEIS at the University of Tokyo. His research interests lie in solving atypical speech phenomena, such as L2 speech, accented speech, and pathological speech, using deep learning and signal processing methods.
Before joining UTokyo, he worked as an AI software engineer at Laronix, an Australian start-up company that developed the world’s first pneumatic larynx. In this role, he was responsible for evaluating and improving the speech quality of products designed for the voice loss community. He earned his M.S. and B.S. degrees from Nagoya University and Dalian University of Technology (DLUT), respectively.
📣 News
-
[Feb 2026] 🥈 Our team Utokyo ranked 2nd Place in the Iqra’Eval2 Challenge at INTERSPEECH 2026!
Check out our Prompt-free MDD paper, Code and Checkpoints! -
[Aug 2025] 🚀 We have open-sourced the full implementation of IF-MDD, our prompt-free paradigm for mispronunciation detection and diagnosis!
-
[Feb 2025] 🎉 Our paper on Perception-Based L2 Intelligibility has been accepted for presentation at INTERSPEECH 2025!
Read the Paper and explore the Demo of our shadowing-based framework.
📝 Publications
-
Subphonetic Acoustic Modeling via Optimal Transport for Pronunciation Assessment
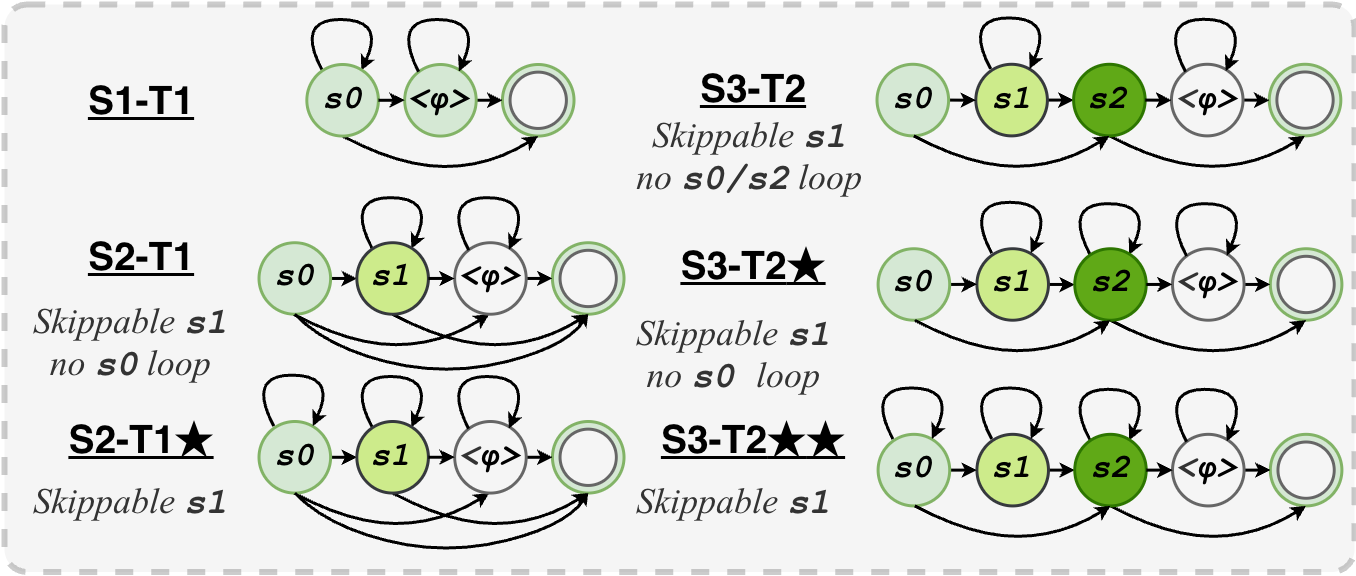
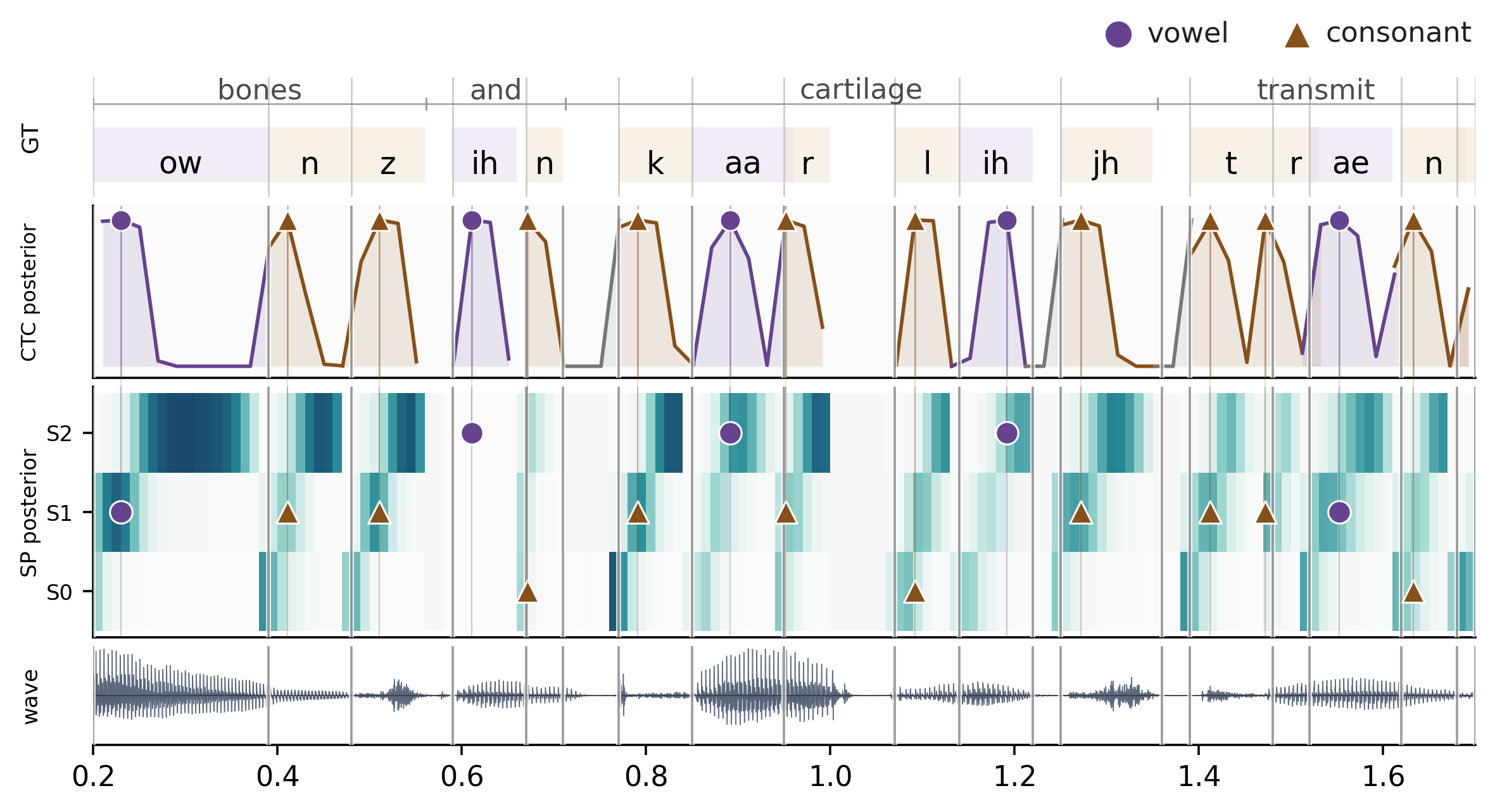
Double Blind Review.- Subphonetic Acoustic Modeling - Expands each phone into ordered internal states, producing dense frame-level acoustic evidence beyond sparse CTC peaks.
- Optimal Transport Training - Learns monotonic frame-to-state alignments with topology-aware optimal temporal transport, without requiring manual frame labels.
- Pronunciation Assessment - Provides more precise phone-internal timing and acoustic cues for segmentation, mispronunciation detection, and automatic pronunciation assessment.
-
Beyond Acoustic Sparsity and Linguistic Bias: A Prompt-Free Paradigm for Mispronunciation Detection and Diagnosis
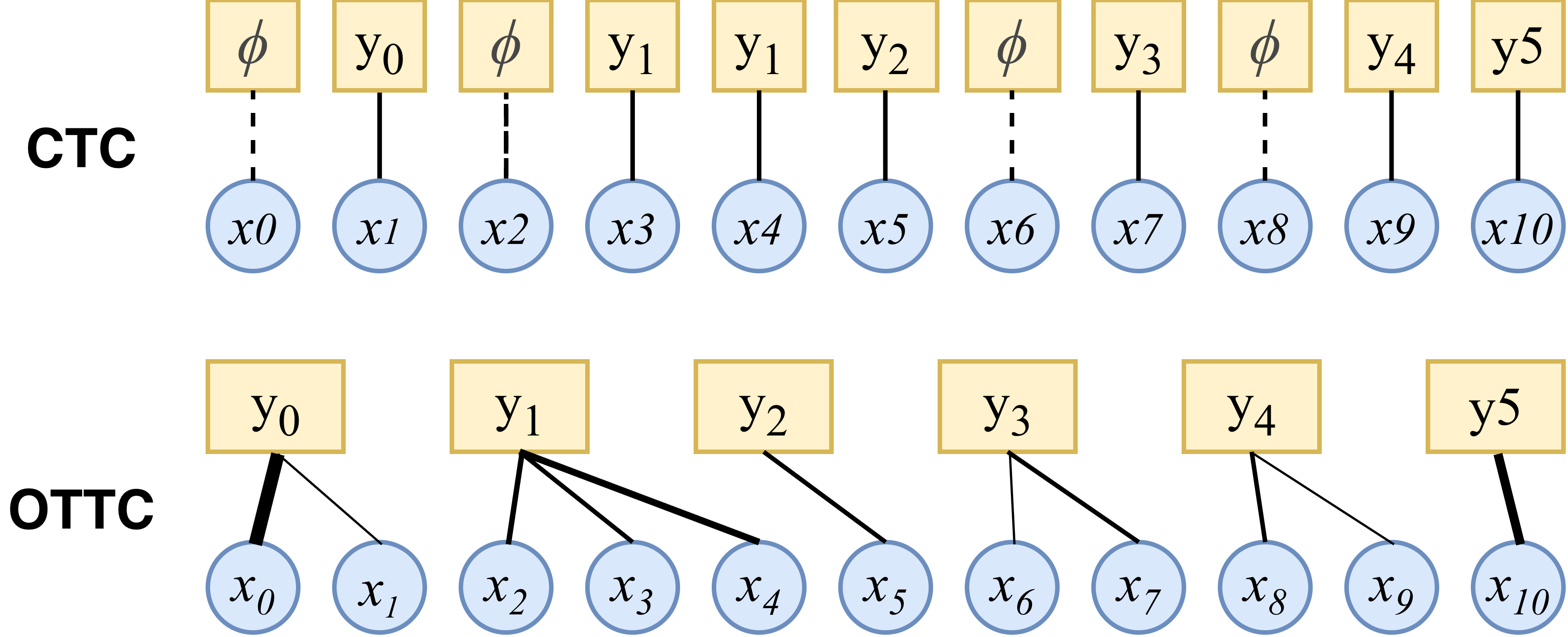
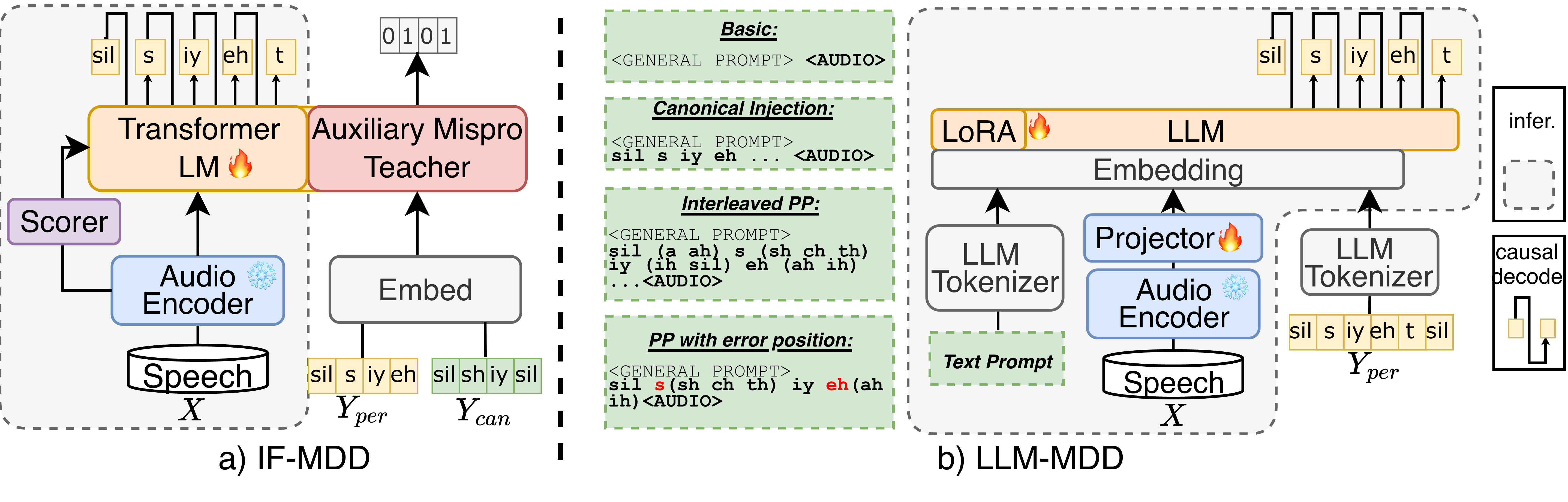
Haopeng Geng, Longfei Yang, Xi Chen et al.🥈 Ranked 2nd in the Iqra'Eval2 Challenge 2026!!- CROTTC Front-end - Proposed a highly sensitive acoustic front-end to capture fine-grained phonetic deviations, effectively mitigating the acoustic sparsity inherent in traditional CTC-based MDD systems.
- Indirect Fusion & Prompt-free Inference - Developed a knowledge transfer paradigm to integrate pronunciation-specific cues into language models, enabling prompt-free inference while maintaining highly competitive cross-lingual performance.
- LLM Limitation Analysis - Conducted a systematic investigation into why Large Language Models struggle with faithful, fine-grained phonetic recognition, shedding light on the critical trade-off between linguistic priors and acoustic evidence.
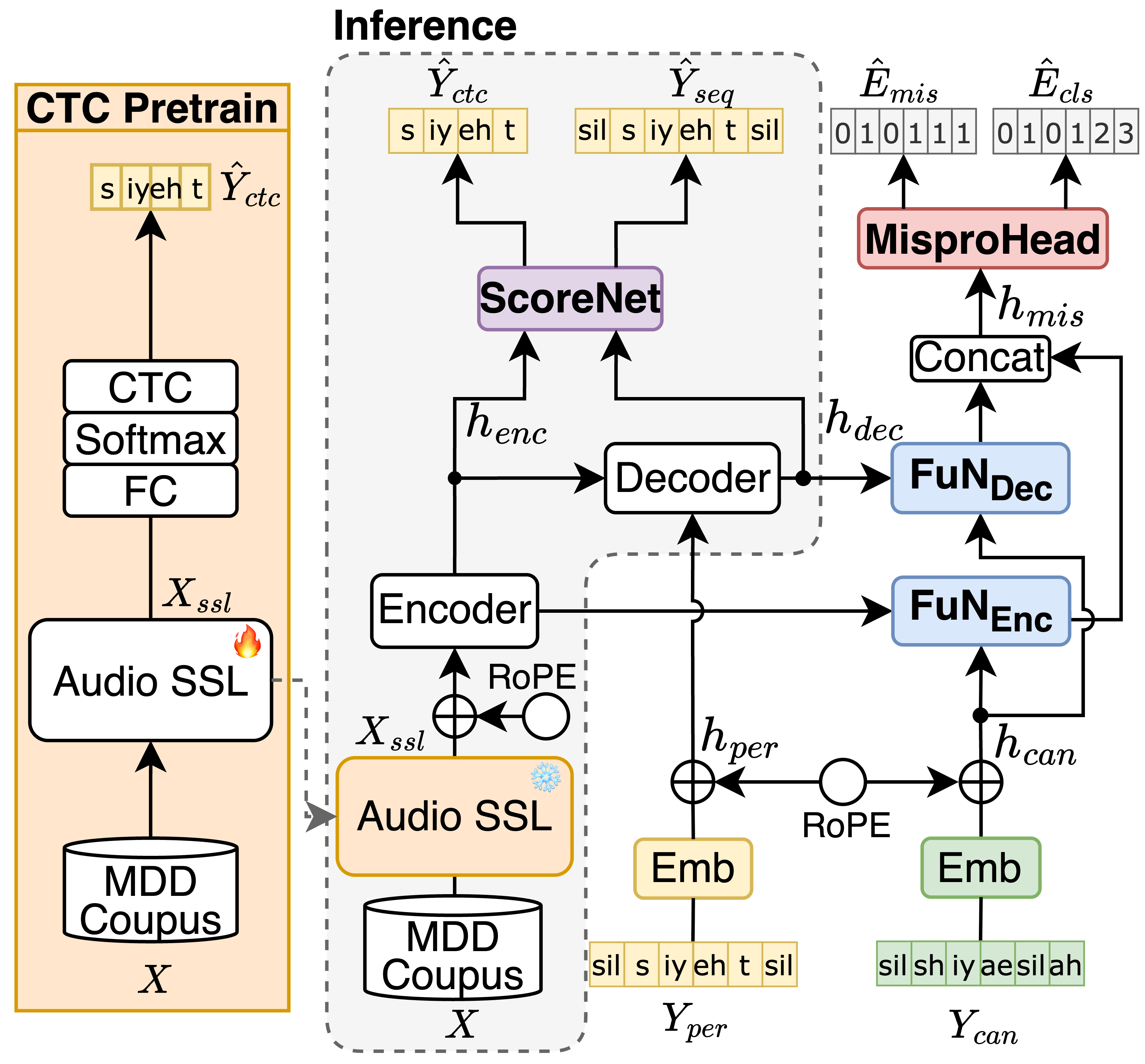
- IF-MDD: Indirect Fusion for Prompt-free Mispronunciation Detection and Diagnosis
Haopeng Geng, Daisuke Saito, Nobuaki Minematsu.
🎧Demo, 💻Github Repo
- Prompt-free Mispronunciation Detection - Developed IF-MDD, an indirect fusion framework that leverages canonical phonemes only during training, enabling inference without text prompts.
- Strong Diagnostic Performance - Achieved 60.67% F1 and 19.98% error diagnosis rate on L2-ARCTIC, showing competitive results even with limited training data.
- Robust Generalization - Demonstrated reliable performance across unseen speakers from diverse L1 backgrounds, highlighting scalability for real-world CALL applications.
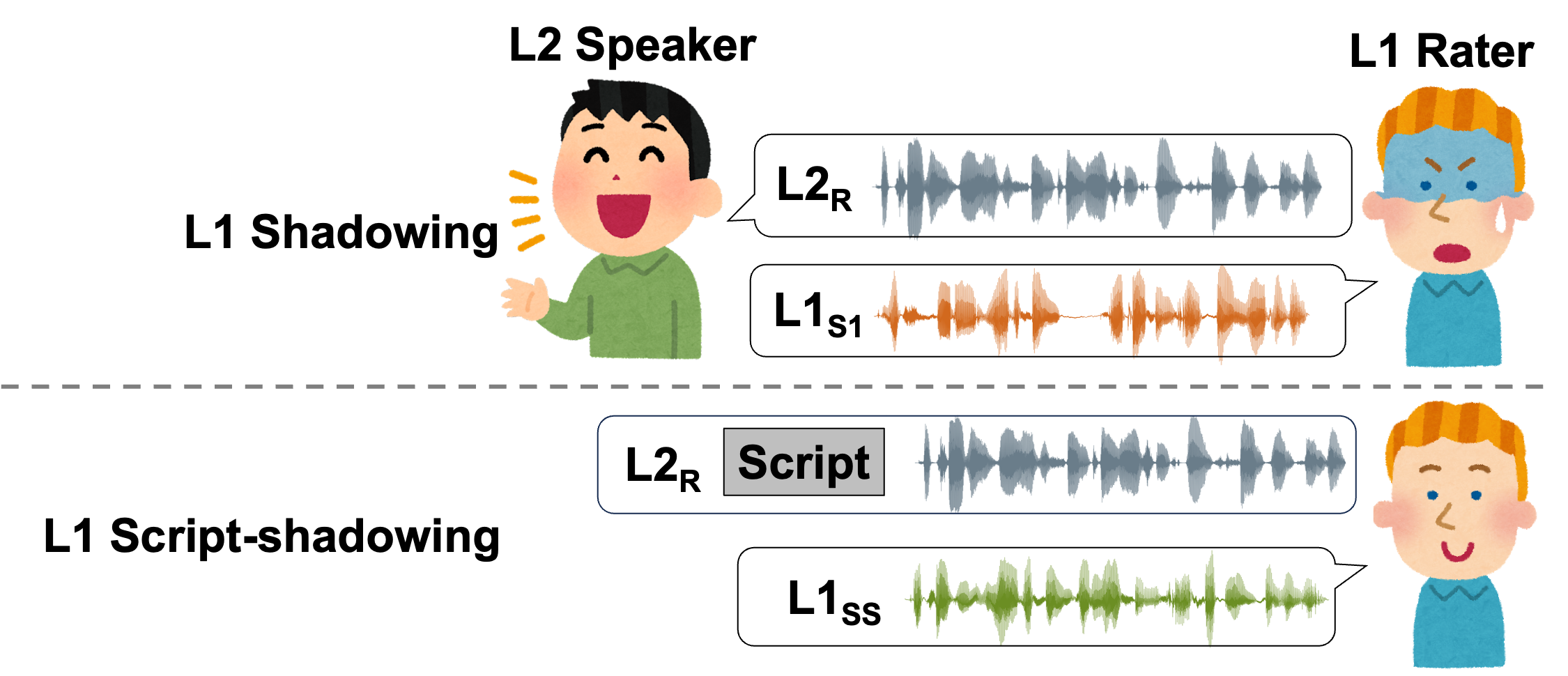
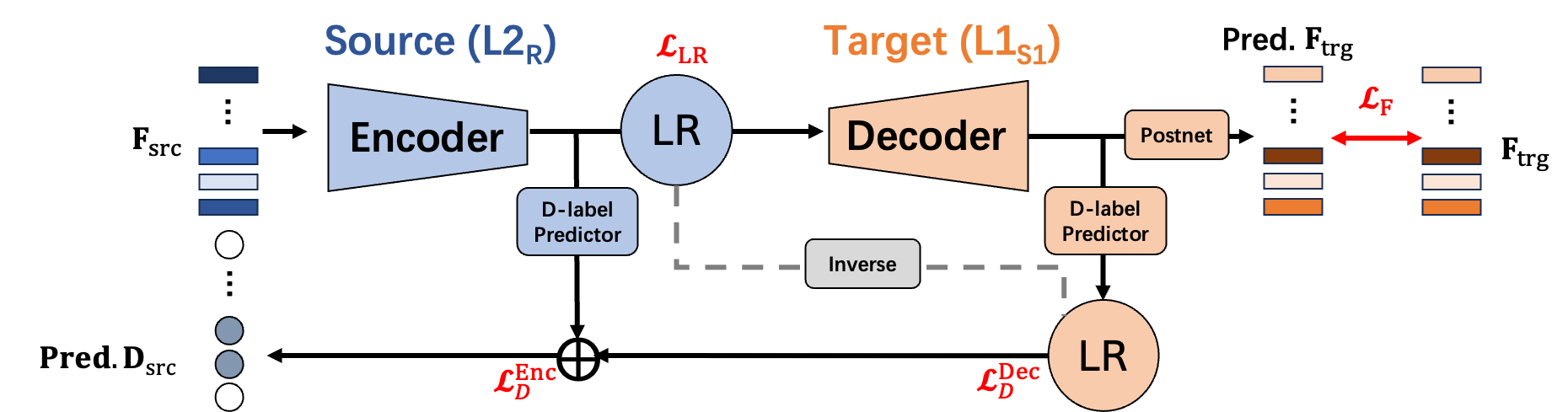
- A Perception-Based L2 Speech Intelligibility Indicator: Leveraging a Rater’s Shadowing and Sequence-to-sequence Voice Conversion
Haopeng Geng, Daisuke Saito, Nobuaki Minematsu.
🎧Demo- Customized Intelligibility Indicator – Proposed a novel metric leveraging native raters’ shadowing data, focusing on perceptual cues rather than purely native-like pronunciation.
- Seq2Seq Voice Conversion Framework – Applied alignment and acoustic reconstruction modules to simulate how native listeners detect unintelligible segments.
- Multi-Task Learning for Feedback – Jointly optimized speech reconstruction and disfluency detection, achieving closer alignment with native raters’ judgments than mainstream ASR and enabling more personalized CALL feedback.
-
SlaTE 2025
Synthesizing True Golden Voices to Enhance Pronunciation Training for Individual Language Learners
Ryoga Yamanaka, Kento Osa, Akari Fujiwara, Haopeng Geng, Daisuke Saito, Nobuaki Minematsu, Yusuke Inoue. -
Submitted to ICASSP 2025
Simulating Native Speaker Shadowing for Nonnative Speech Assessment with Latent Speech Representations
Haopeng Geng, Daisuke Saito, Nobuaki Minematsu
🎧Demo -
APSIPA ASC 2024
A Pilot Study of Applying Sequence-to-Sequence Voice Conversion to Evaluate the Intelligibility of L2 Speech Using a Native Speaker’s Shadowings
Haopeng Geng, Daisuke Saito, Nobuaki Minematsu. Accepted by APSIPA 2024.
🎧Demo, 💻Github Repo -
ASJ 2022
Disfluency Removal with Speech Inpainting on Spontaneous Lecture Speech
Haopeng Geng, YASUDA Yusuke, Tomoki Toda.
📖 Educations
- 2024.04 - Present,
- Ph.D Candicates. in Engineering, The University of Tokyo, Japan.
- Supervisor: Prof. Nobuaki Minematsu.
- 2020.04 - 2022.03
- M.S. in Informatics, Nagoya University, Japan.
- Supervisor: Prof. Tomoki Toda.
- M.S. in Informatics, Nagoya University, Japan.
- 2014.09 - 2019.06
- B.S. in Computer Science and Technology, Dalian University of Technology,
- B.A. in Japanese, Dalian University of Technology, China.
💬 Work Experiences
- 2022.07 - 2023.12, Technical Assistant, Nagoya University,
- 2022.03 - 2024.10, AI Software Engineer, Laronix, Australia.
🎖 Honors and Awards
- 2026.02 Iqra’Eval2 Challenge 🥈 2nd place, INTERSPEECH 2026.
- 2024.03 SPRING-GX Scholarship, University of Tokyo.
- 2022.04 Graduate program for real-world data circulation leaders, Nagoya University.
- 2017.09 Scholarship for outstanding undergraduate students, CSC.
💻 Internships
- 2025.03 - 2025.09, Software Engineer, CoeFont,
- 2025.01 - 2025.09, Research Assistant, Carriage inc.,
- 2021.08, NTT Human Informatics Laboratories, Japan.